How We Generate Our New Documentation with Sanity & Nuxt.js
In a rush? Skip to technical tutorial
We’ve spent the last few months building the new version of our shopping cart.
When we started working on it, we knew this would also mean changes in other areas of our product.
Documentation was one of them.
It meant a few specific and much-needed upgrades:
Improving navigation between docs versions
Rethinking content arborescence
Automating documentation generation as much as possible
We also wanted to stay true to what we preach; using the JAMstack! That meant choosing the right JavaScript tools to generate our documentation.
We ended up picking Nuxt for static documentation generation, Sanity.io to manage content, and Netlify for automated deployment. I’ll explain why later on.
In the end, it was a great opportunity to significantly enhance our docs UX for both users and our development team.
In this post, I want to show you how we did it and how you can replicate it.
Disclaimer: Keep in mind this is an ongoing beta of the v3.0 for development and testing purpose only.
Our documentation generation (a bit of context)


Our old doc was built with custom Node.js and needed server-side rendering on each new page load. We often forgot to document new fixes and simple features. There was also the unfortunate errors and typos from time to time. In short, documentation could often become a pain in the a**. I’m sure some of you can relate to this.
So, for our new documentation, we fixed ourselves a few goals. It had to:
Be deployed as a fully static site
Be hosted on a fast CDN
Use Vue.js on the frontend (as it’s our team’s go-to framework)
Make editing content easier for the whole team—not only devs!
Ensure all our Javascript API’s methods and theme’s overridable components get properly documented
This combination of criteria added up to an obvious choice of stack: a Vue-powered static site generator attached to a headless CMS.
As automation fans, we didn’t want to manage the documentation of our theme’s components and the Javascript API independently. The documentation data would need to be generated at build time from the code and JSDoc comments.
This would require a fair amount of additional work but, in the long run, ensure documentation that’s always up-to-date and validated at the same time we review features’ pull requests.
This also added the constraint of choosing a headless CMS with a powerful API to update content.
Why Sanity as a headless CMS?


There are many, many headless CMSs. I suggest doing a thorough research and measure the pros and the cons before choosing one. In our case, there are a few criteria that made the balance lean in favor of Sanity.io:
Great out-of-the-box editing experience
Fully hosted—no need to manage this in our infrastructure
Open source and customizable
Excellent API for both querying & writing
Webhooks allowing us to rebuild the doc after content edits
Starting a Sanity project is straightforward. In a newly created repo, run sanity init.
Then, define a few document types and, if your heart feels like it, create some custom components to tailor editing to your specific needs. Even if you embark on a customization spree, this won’t prevent you to from deploying your CMS on Sanity—that’s where it truly shines, because high customizability is quite a rare trait in hosted solutions.
Sanity’s API was also a breath of fresh air.
GROQ, their querying language, is a welcome addition to the ecosystem. Think GraphQL, without always being required to be explicit about all the fields you want in a query (or being able to query polymorphic data without feeling like the Labours of Hercules).
Furthermore, modifications can be scoped in a transaction which allows us to batch updates to multiple documents from our theme and SDK build process. Combine this with webhooks, and it ensures we only trigger documentation deploys once for many changes from our theme and SDK repositories.
Why Nuxt as static site generator?

Just when you thought there was a lot of headless CMSs to choose from, you stumble upon the dozens of existing SSGs.
The main requirements for our static site generator were:
Deploys only static files
Uses Vue.js
Fetches data from an external API
The use of Vue.js may seem arbitrary here, and you would be right to ask: “Why not react or something else?” In all fairness, it was initially a bit arbitrary as it amounts to the team’s personal preferences, but as we build more and more projects, we also value consistency across all of them.
We’ve been using Vue.js for a long time in the dashboard, and we went all in for our default v3.0 theme. Eventually, that consistency will allow us not only faster onboarding of team members but also code reuse. Let say we would want to build a live preview of theme customization; sharing the same stack between the docs and the theme makes that easier.
That being said, it left us with three SSG contenders: VuePress, Nuxt & Gridsome.
→ VuePress. Having built-in support for inline Vue components in content was really tempting, but without the option to tap in an external data source instead of local markdown files, it was a no go.
→ Nuxt.js. This one is a power-horse of SPA development with Vue. It offers a great structure and just the right extension points to be truly flexible. The nuxt generate command allows to deploy a fully static and pre-rendered version of the website. However, building a content-driven website instead of a dynamic web app requires additional work.
→ Gridsome. Being directly inspired by Gatsby, it has first class support for external data sources, and it was created to build static websites from this data. Having experimented with it already and because it checked all the boxes, Gridsome first seemed like the chosen one.
However, we quickly stumbled upon some pain points:
The automatic generation of the GraphQL schema has some issues and often requires to specify the type of fields manually.
We couldn’t structure our data as we wanted. We had to store
function,classandenum, which all needed to be associated with documentation pages in a polymorphic way.Let’s be honest, having to deal with GraphQL schema simply slows down iteration cycles.
Overall, Gridsome lacked a bit of maturity when it comes to a complex schema. As for GraphQL, it excels in scenarios where you have multiple data consumers interested in different queries. In our case, this only added unnecessary steps.
In the end, we chose to use Nuxt and to develop the missing pieces manually.
With Gridsome 0.7, you can specify GraphQL schema types and comes with a Sanity data source plugin.
All that’s missing at this point is something to deploy our documentation. For us, there was no debate. Netlify is a no-brainer here, so it became the last missing piece in our stack.
Our new documentation generation, Javascript style
Before diving into technical nitty-gritty stuff, let’s have a look at that stack all wired together. JAMstack projects may sometime feel overwhelming because of the number of tools used, but it allows you to pick them for their specific value.
Although some individual parts are relatively complex, putting them all together was quite easy.

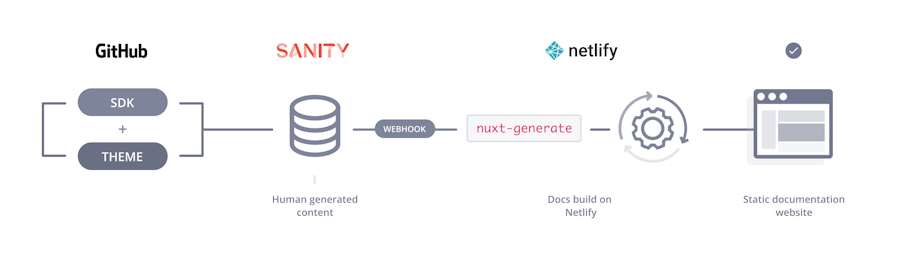
Our documentation is composed of traditional content pages written by our dev or marketing team and technical content extracted from two repositories:
The Javascript SDK’s doc (similar to our handcrafted V2’s Javascript API)
The Vue.js theme components’ doc (new to the v3.0 for component overriding)
Content pages get edited directly in Sanity CMS. For the technical content, it gets generated automatically using Typescript’s compiler API and pushed to Sanity’s API in a script on our CI when each repo is updated. That script uses Sanity’s transaction feature to update all modifications at once.
Changes from Sanity generate a webhook that we use to trigger a build on Netlify. Handling webhooks in a JAMstack setup often requires to use some kind of Lambda function as a logic layer between the source’s webhook and the target’s API.
However, here we can leverage clever foresight from Netlify. Their incoming webhook endpoint is a simple private URL that accepts any POST request to trigger a build—meaning Sanity’s webhook can be configured directly to it!
Once the build is started, it runs nuxt generate. Our custom code fetches data from Sanity, and the dist folder get deployed on a blazing fast CDN.
In a nutshell, Sanity is used as a store of all that’s needed in our docs. The documentation itself is always up-to-date with anything that gets released in production. Documentation coming from sources can be validated as part of a regular code review process.
Generating documentation from sources
All our v3.0 projects being in Typescript, it allows us to exploit its compiler API to extract documentation from source code. This happens in three phases:
The compiler automatically generates type definitions (a
.d.tsfile) of the project excluding every type marked as internal (using@internaltags in JSDoc comments). This is accomplished simply by settingdeclarationandstripInternaltotruein ourtsconfig.jsonOur custom script is executed; it reads the
.d.tsfile, parse it with the compiler API and passes the result to a library called readts which transforms the compiler’s output into a more manageable data structure.Finally, our script update Sanity’s database using their npm module.
Let’s take this function as an example:
/**
* Initialize the SDK for use in a Web browser
* @param apiKey Snipcart Public API Key
* @param doc Custom document node instead of `window.document`
* @param options Initialization options
*/
export async function initializeBrowserContext(
apiKey?: string,
doc?: HTMLDocument,
options?: SnipcartBrowserContextOptions) : Promise<SDK> {
// some internal code
}It gets exported in our SDK’s type declaration almost as is, minus the method’s body. The following code allows us to convert read it in a structured way:
const parser = new readts.Parser();
parser.program = ts.createProgram(["snipcart-sdk.d.ts"]);
parser.checker = parser.program.getTypeChecker();
parser.moduleList = [];
parser.symbolTbl = {};
// the compiler will load any required typescript libs
// but we only need to document types from our own project
const source = parser.program
.getSourceFiles()
.filter(s => s.fileName === "snipcart-sdk.d.ts")[0];
// we instruct `readts` to parse all
// `declare module 'snipcart-sdk/*' {...}` sections
for (const statement of source.statements) {
parser.parseSource(statement);
}
const result = parser.moduleList.map((module) => {
/* some more transformations */
});Once uploaded to Sanity’s dataset, the previous function declaration ends up looking like this:
{
"_id": "sdk-contexts-browser-initializeBrowserContext",
"_type": "sdk-item",
"kind": "function",
"name": "initializeBrowserContext",
"signatures": [
{
"doc": "Initialize the SDK for use in a Web browser",
"params": [
{
"doc": "Snipcart Public API Key",
"name": "apiKey",
"optional": true,
"type": {
"name": "string"
}
},
/* other params */
],
"returnType": {
"id": "sdk-core-SDK",
"name": "SDK"
},
}
]
}Using readts may make it look like a walk in the park, but using Typescript’s compiler API isn’t for the faint of heart. You’ll often have to dive into the compiler’s Symbols (not to be confused with those from the language), the AST nodes and their SyntaxKind enum values.
The data now being ready to be consumed by our SSG, let’s see how we wired Nuxt!
Making Nuxt fully static and content driven
Through its nuxt generate command, Nuxt.js can generate a fully static website at build time.
However, contrary to Gatsby or Gridsome, which cache the content nodes, fetching of data is still performed even in static mode with Nuxt. It happens because the asyncData method is always called, and it’s up to the developer to provide distinct logic if wanted. There are already some talks about fixing this in the Nuxt community. But we needed it NOW 🙂
We approached that issue with a Nuxt module that has different behaviors when called from the client (the static website) or the server (when nuxt generate is called). That module gets declared in our nuxt.config.js:
modules: [
"~/modules/data-source",
],Then, it simply registers a server and client plugin:
export default async function DataSourceModule (moduleOptions) {
this.addPlugin({
src: path.join(__dirname, 'data-source.client.js'),
mode: 'client',
});
this.addPlugin({
src: path.join(__dirname, 'data-source.server.js'),
mode: 'server',
});
}They both expose the same method on every page's component to load data. What differs is that on the server, that method directly call Nuxt API to retrieve content:
// data-source.server.js
import { loadPageByUrl } from '~/sanity.js';
export default (ctx, inject) => {
inject('loadPageData', async () => {
return await loadPageByUrl(ctx.route.path);
});
}On the client, the plugin will instead load a static JSON file:
// 'data-source.client.js'
import axios from 'axios';
export default (ctx, inject) => {
inject('loadPageData', async () => {
const path = '/_nuxt/data' + ctx.route.path + '.json';
return (await axios(path)).data;
});
}Now, in our page’s component, we can blindly call loadPageData and the module and plugins will guaranty that the proper version is used:
<!-- page.vue -->
<template>
<Markdown :content="page && page.body || ''" />
</template>
<script>
import Markdown from '~/components/Markdown';
export default {
props: ['page'],
components: {
Markdown,
},
async asyncData() {
return await app.$loadPageData();
}
}
</script>Here’s a sneak peek of how the function I’ve talked earlier look like in the doc:

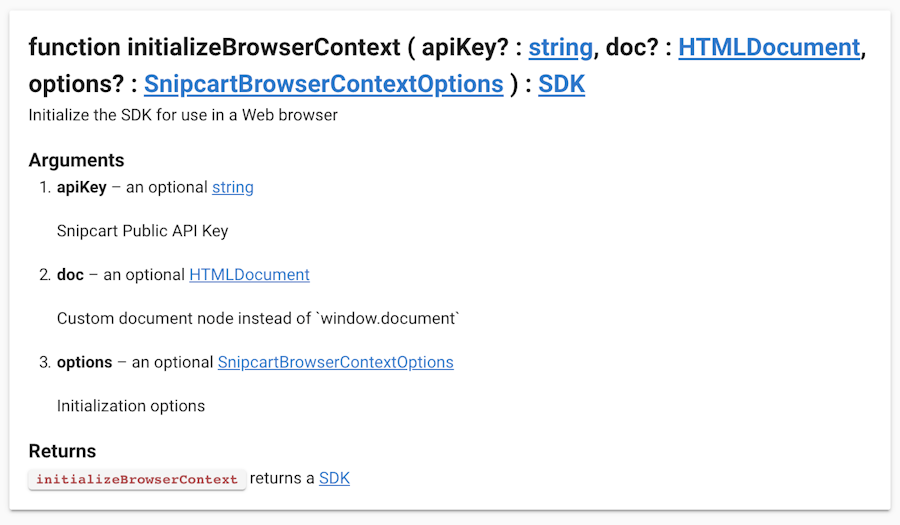
The final result

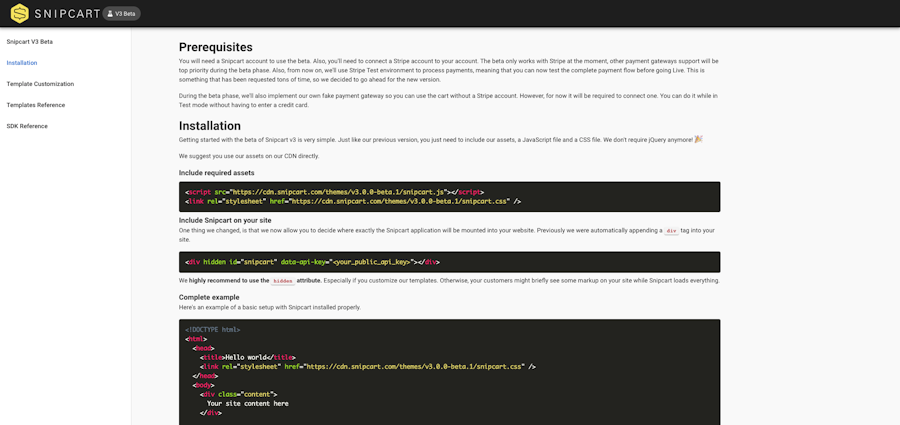
You can visit the docs here.
Try out Snipcart v3.0 right now! It's free to sign up.
Closing thoughts
Getting started on Sanity was a breeze, and while we didn’t push it far yet, everything looks purposefully built to be extended smoothly. I was really impressed by their API, querying with GROQ, and how plugins can be crafted for the CMS.
As for Nuxt, although it required more work for our use case, it still provides a strong base to build any Vue.js project with.
With all that crunchy groundwork done, we’re ready to tackle more cosmetic improvements to the documentation, like better discoverability and organization of our SDK methods.
If you've enjoyed this post, please take a second to share it on Twitter. Got comments, questions? Hit the section below!




