Using Next.js with FaunaDB: How to Query the Database from Your App
What distinguishes plain static sites from Jamstack sites?
Their use of data from APIs.
While a traditional static site might use file-based data like Markdown and YAML, a Jamstack site frequently uses things like a headless CMS or e-commerce.
Headless CMS and API-driven services like Algolia fill many needs but are built for particular purposes. Your Jamstack site might need to store and access data that doesn't fit into the CMS archetype, for instance. In those cases, you might need a... database!
Fauna is one solid option. It is a cloud-based transactional serverless database that makes that data available via a data API. This makes it ideal for use in a Jamstack application.
A great piece about FaunaDB with its CEO here.
This article will explore how to get started using FaunaDB and Next.js to connect a database to a Jamstack site built in the React framework.


We'll cover:
More about serverless architectures here.
Setting up FaunaDB
Fauna databases provide many ways to get started. You can use the web-based admin to create and manage new databases. However, you can also do most actions via the Fauna Shell, a CLI for interacting with Fauna, which is what we'll use for this tutorial.
npm install -g fauna-shellNow we can log in.
fauna cloud-loginYou'll need to enter your email and password. If you signed up using third-party authentication like Netlify or GitHub, you need to create the database via the web admin and get a security key in the security tab of the database.
Fauna documentation about cloud-login here
We'll create a simple application using Next.js that will be a list of shows that I want to watch. Let's create a new database to store this data.
fauna create-database my_showsAt this point, we can use the shell to interact with the database and create new collections, which are Fauna's equivalent of a table.
fauna shell my_showsYou should see something like the following:
Starting shell for database my_shows
Connected to https://db.fauna.com
Type Ctrl + D or .exit to exit the shell
my_shows> Using FQL (Fauna Query Language) to create and query data
Once inside the shell, you can interact with your new database using FQL (Fauna Query Language). FQL is essentially Fauna's API language for creating, updating, and querying data. However, it isn't an API in the way you're probably used to using one. It includes things like data types, built in functions and even user defined functions that make it feel more like a programming language than a typical API. There's a lot you can do with FQL, more than we can cover in-depth here. Be sure to refer to the documentation for a full overview.
Let's start by creating a collection called "shows."
CreateCollection({ name: "shows" })A collection in Fauna stores documents. If you are more comfortable with a traditional relational database model, you can think of these as table rows. We could create a single document using the Create() method, but instead, populate multiple documents using the Map() method. We'll map over a nested array of values. Each of the nested arrays represents the values of one document. We'll use these to populate the two properties in our document, title and watched. For now, we'll set watched on all these dummy items to false to indicate we have not yet watched them.
Map(
[
["Kim's Convenience",false],
["I'm Sorry",false],
["The Good Place",false]
],
Lambda(["title","watched"],
Create(
Collection("shows"), { data: { title: Var("title"), watched: Var("watched")} }
)
)
)Lastly, let's query for all the documents in our "shows" collection. In this case, we'll use Collection() to define which collection we are pulling from, Documents() to say that we want all the references to each document in our shows collection, and then Paginate() to convert these references to Page objects. Each page will be passed to the Lambda() function, where they will be used to Get() the full record.
Map(
Paginate(Documents(Collection("shows"))),
Lambda(show => Get(show))
)You should see a result like:
{
data: [
{
ref: Ref(Collection("shows"), "293065998672593408"),
ts: 1615748366168000,
data: { title: "I'm Sorry", watched: false }
},
{
ref: Ref(Collection("shows"), "293065998672594432"),
ts: 1615748366168000,
data: { title: 'The Good Place', watched: false }
},
{
ref: Ref(Collection("shows"), "293065998672595456"),
ts: 1615748366168000,
data: { title: "Kim's Convenience", watched: false }
}
]
}Finally, before we move on, we should create an index for this collection. Among other things, the index will make it easier to locate a document, updating the records easier.
CreateIndex({
name: "shows_by_title",
source: Collection("shows"),
terms: [{ field: ["data", "title"] }]
})Now that we have our database created and populated let's move to use it within a Next.js app.
Getting data in Next.js with FaunaDB
We're going to walk through creating a simple web app using Next.js that uses our Fauna table to allow us to add shows we want to watch and mark the shows we've watched as done. This will demonstrate how to read data from Fauna and display it in Next.js, create new records in Fauna, and update an existing record.
The code for this sample is available in GitHub. It borrows the layout from this CodePen. You can see what the app looks like below.

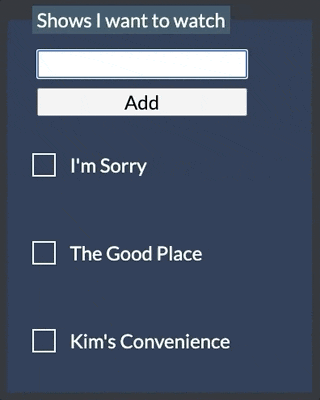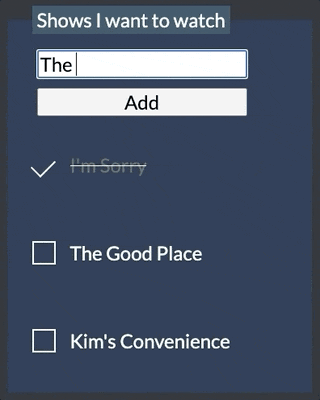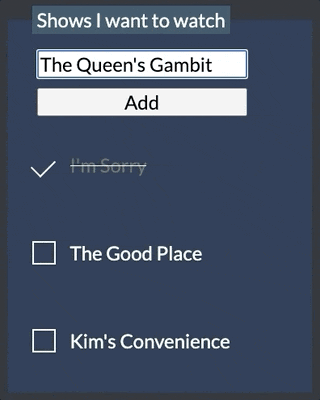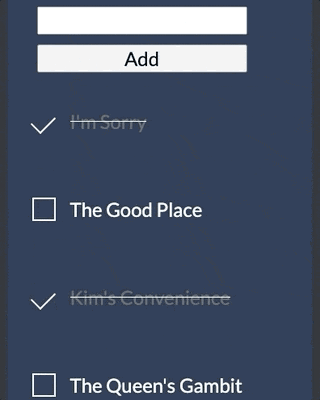
To use the sample yourself, you'll need to provide a .env file with a value for FAUNADB_SECRET that contains a key from Fauna to connect to your shows collection. To obtain a key, go to the "Security" tab within your collection on the Fauna dashboard and create a new key.
We won't cover every detail of building a Next.js app here as it is just a single page. We'll explore some of the basic pieces that you need to understand to use Fauna.
You can follow this tutorial from Vercel to get started with Next.js
Fauna JavaScript driver
To query Fauna within our app, we're going to use the Fauna JavaScript driver. This is a Node.js library for integrating with Fauna. It allows you to run the same FQL queries that we ran within the Fauna Shell from your Node application. To add this to a new Next.js application, you need to run:
npm install faunadbWithin Node, you need to instantiate the client with your Fauna key. We can do this from within a /lib/fauna.js file that we will include wherever we need to access data in Fauna. It gets the key from an environment variable called FAUNADB_SECRET that is within a .env.local file.
import faunadb from 'faunadb';
export const faunaClient = new faunadb.Client({
secret: process.env.FAUNADB_SECRET,
});Protecting your API key
Before we begin getting data, there's one area of concern. Since our application data is all user-generated, it is getting all of its Fauna data client-side rather than at build time. This means that anyone inspecting the API call would have access to the Fauna key.
There are two ways to handle this:
1. Create a key that has very restricted permissions set within the Fauna dashboard to limit misuse.
This still exposes the key but limits the potential for misuse. It's handy if you are reading data and limit the key to read-only.
2. Create a serverless function that is an intermediary for calling the Fauna API, thereby hiding your key entirely.
This is the more secure option because it never exposes the key at all. Users can still call the endpoint if they inspect how, but the API limits what they can do.
Luckily, within Next.js, there is an easy way to accomplish the second option by using Nextjs API routes.
All of the interaction with Fauna within this sample app will go through one of three API routes: getShows; addShows; or updateShows.
Getting data from Fauna database
From a Fauna Query Language standpoint, reading data from Fauna is pretty straightforward. We'll use the same Map() function we used within the Fauna Shell earlier. We need to do it in the context of the client that we instantiated earlier.
The methods are all derived from an instance of the query object from the Fauna JavaScript driver. Otherwise, the query itself is the same.
import { query as q } from 'faunadb';
import { faunaClient } from '../../lib/fauna';
export default async (req, res) => {
if (req.method == 'GET') {
let query = await faunaClient.query(
q.Map(
q.Paginate(q.Documents(q.Collection('shows'))),
q.Lambda((show) => q.Get(show))
)
);
res.status(200).json({ data: query.data });
}
};To call this from within our app when the page loads, we'll first instantiate a new state variable with our shows array:
let [shows, setShows] = useState([]);Then from within the useEffect React hook, we can call the API endpoint and populate the results with the data returned from Fauna.
useEffect(async () => {
let showData = await fetcher('/api/getShows');
setShows(showData.data);
}, []);Adding data to FaunaDB
Next, let's look at the createShows API endpoint. To add a single row to our shows collection, we'll use the Create() method within FQL. We provide it an instance of the collection we are writing to and a structure containing the data we want to write.
export default async (req, res) => {
if (req.method == 'POST') {
const body = JSON.parse(req.body);
let query = await faunaClient.query(
q.Create(q.Collection('shows'), {
data: { title: body.title, watched: false },
})
);
res.status(200).json({ data: query });
}
};We're defaulting a new show to watched: false but populating the title with whatever is passed.
(Note: for the sake of simplicity, I have not added a lot of error checking to this application, meaning calling this method without a title will fail).
Now let's use this API endpoint by first instantiating another state variable to hold the new show data entered into the form.
let [newShow, setNewShow] = useState('');We also need to add a function that will be the onChange handler for the form input.
function handleNewShow(e) {
setNewShow(e.target.value);
}Finally, we need a method to handle when the user clicks on the "Add" button to submit a new show. This method calls our addShows API endpoint. That endpoint returns the new show data that was just added to Fauna.
We then append that to the array of shows so that our UI will update with the show we just added.
Finally, we clear the form input by emptying the value of the newShow state variable.
async function handleAddShow() {
const res = await fetch('/api/addShows', {
method: 'POST',
body: JSON.stringify({
title: newShow,
}),
});
const body = await res.json();
// add the new show to the existing list
let newShows = shows.slice();
newShows.push(body.data);
setShows(newShows);
setNewShow('');
}Updating data in Fauna
Finally, we want to be able to check and uncheck a show as having been watched. To do that, we need to update a record in Fauna.
This is where the index we added earlier will come in handy as it allows us to easily get a reference to the record using the show title. We use that reference to get an instance of the record and then update the record with the new data, which is watched as either true or false.
export default async (req, res) => {
if (req.method == 'POST') {
const body = JSON.parse(req.body);
let query = await faunaClient.query(
q.Update(
q.Select(
['ref'],
q.Get(q.Match(q.Index('shows_by_title'), body.title))
),
{
data: {
watched: body.watched,
},
}
)
);
res.status(200).json({ data: query });
}
};Next, we'll add a click handler for the checkbox inputs that will call the updateShow API endpoint.
To update the UI, we loop through the show state variable and update the watched value on the proper show. Once the state is updated, the show will mark as watched or unwatched accordingly.
async function handleUpdateShow(e) {
const res = await fetch('/api/updateShow', {
method: 'POST',
body: JSON.stringify({
title: e.target.value,
watched: e.target.checked,
}),
});
let newShows = shows.slice();
newShows = newShows.map((show) => {
if (show.data.title == e.target.value) {
return Object.assign({}, show, {
data: { title: e.target.value, watched: e.target.checked },
});
}
return show;
});
setShows(newShows);
}Where to go from here
Obviously, this is a simple example, but hopefully, it gave you a solid sense of working with Fauna. There is much more that you can do with Fauna than we've covered here.
For example, if you prefer to work with GraphQL rather than Fauna's FQL for querying, Fauna gives you the ability to upload a GraphQL schema and then use GraphQL for querying rather than FQL.
There's even a Next.js starter providing an example of how to use Fauna with GraphQL inside a Next.js app.
Fauna offers built-in identity and authentication that you can use to add a login to your Jamstack site. And there's also a streaming feature in the preview that allows you to subscribe to a document so that any time it is updated or deleted, the stream is notified. Basically, this lets you push changes from Fauna to the client whenever data is updated.
It's worth giving Fauna a try - there's a generous free tier that you can do quite a lot with. Go ahead and put some data in your Jam.
If you've enjoyed this post, please take a second to share it on Twitter. Got comments, questions? Hit the section below!




