Making Sense of Jamstack & Serverless Architecture Backend
It feels like the modern web has become synonymous with buzzwords. These terms can be confusing and hard to really understand.
Two of these buzzwords are hard to distinguish for some: Jamstack and serverless.
They are two powerful architectures that help developers build great experiences for the web—but are they just two buzzwords without much substance? What do they actually mean, and are they the same thing?
Let's start with the basics.
What is the Jamstack?
Jamstack is an architecture that focuses on two points: serving a website or application statically on request and precompiling or prerendering as much of that experience as possible before the HTML reaches the browser. That experience can even be made dynamic by taking advantage of clientside requests and in-browser capabilities.


This idea was popularized by static site generators and frameworks that would pull together dynamic content to produce a website or application statically. That application would eventually be served straight from static storage.
Bringing together a "mesh" of services
The idea of the Jamstack would grow to include strategic modularity of application infrastructure, where maybe it doesn't make as much sense to build an entire stack of features on one server.
Instead, that infrastructure would be divided into components or microservices where the frontend would be the hub to tie all of these services together, sometimes referred to as the "mesh".


Gatsby's content "mesh" via https://www.gatsbyjs.com/blog/2018-10-04-journey-to-the-content-mesh/
Instead of building a specific component yourself, you could use third-party services like an authentication service or a shopping cart. You wouldn't necessarily need to maintain it yourself, and you can be confident the service will work well.
Building better experiences on the web
Regardless of what mesh of services you use, the goal is to eliminate time spent on a server while the visitor waits for the frontend to load. This directly helps to improve the performance and the UX (User Experience) of the application. This will not only help to keep your visitors but also help with SEO.
It typically also leads to less cost, as static storage is really cheap! And that static storage or static CDN (content delivery network) request can scale infinitely, allowing any number of visitors to hit the core application at once.
What is serverless?
Serverless is an architecture that revolves around the idea that you don't have to "use" or rely on servers in the traditional sense (read: have to build and/or maintain your own server) when building applications. Instead, you take advantage of services typically managed by cloud vendors (AWS, Microsoft Azure, and Google Cloud, etc.) that abstract the server, providing similar capabilities as traditional servers, but in a focused and easy-to-use way.
Compute without the overhead
While technically, everything on the web is running on servers, the goal of serverless is to take away the overhead and maintenance from the developers as if they weren't using servers at all. The cloud provider managing that service is solely responsible for any upkeep typically done with server-based services.
Take a popular serverless technology like serverless functions, for instance, using AWS Lambda. We can run code that would be typically running on a server inside of a "function" without having to touch a server at all.

Just like on the server, that function can make requests, access data, and provide a mechanism to interact with secure resources, but you work within the confines of a single function.
Highly scalable and cost-effective infrastructure
The cloud provider will handle the infrastructure and management of that function. Your goal is to provide the code executed when that function is invoked, like hitting an API that runs that function.
This ends up leading to lower costs, as you only get charged when the function is invoked instead of having to pay for a server constantly running even when unused.
It's also a highly scalable solution. Your functions aren't stuck sharing resources between one or many servers, and their resources are pooled for each invocation.
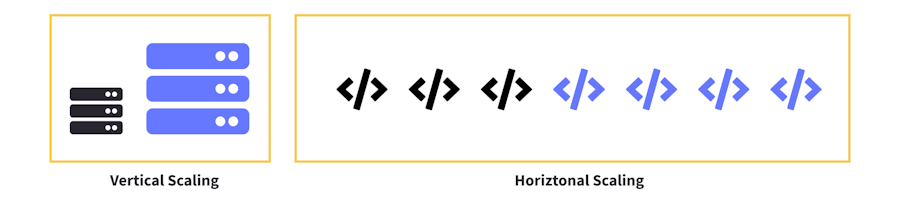
When a traffic spike occurs, the functions are scaled horizontally, meaning more instances of that function are invoked, as opposed to vertically, where you might have something like a server that would instead just get more resources added to it.
Because you can virtually have as many invocations as you want, that's where the idea of "infinitely scalable" comes into play.
Are Jamstack and serverless the same thing?
Technically no, but it's a bit more nuanced as Jamstack and serverless have a lot of overlap.

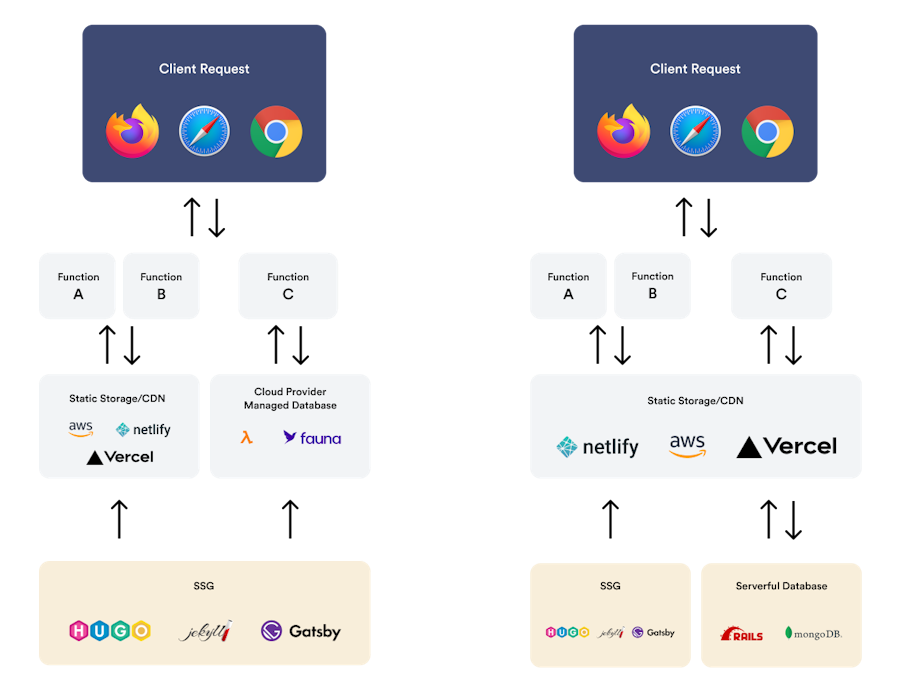
Comparison between serverless Jamstack (left) and serverful Jamstack (right). The yellow row is self-managed as opposed to the light gray row that a cloud provider manages.
Like I mentioned earlier, Jamstack came from a place where the goal was to serve your website or application from static storage. This is more so on the frontend of your application, which involves your HTML documents and static assets.
Static storage itself is a serverless solution, as it doesn't include the overhead of maintaining a server to ultimately serve those files.
On the other hand, serverless doesn't necessarily mean you're building with a Jamstack architecture. Serverless typically refers to how you're working with your backend but can also include some of the same key components of a Jamstack architecture.
You may still be serving your application server-side rendered (SSR), but your traditional backend may be using APIs built with serverless functions or serverless databases like DynamoDB.
We can get a good look at the particularities with a few examples.
Let's get practical
Example 1: Jamstack

Frontend: React application served from Netlify (static)
Backend API: Ruby on Rails server
We're working with a static frontend where the HTML and assets are served without any compute happening on request. The application takes advantage of clientside requests, but it hits a Ruby on Rails web server, which isn't a serverless solution.
Example 2: serverless

Frontend: Next.js serverside rendered via Vercel
Backend: serverless functions served from Vercel
Our frontend of the application wouldn't be considered Jamstack. We're using a server to render each and every request. That said, once our application is rendered and in the browser, we take advantage of serverless functions to provide additional dynamic capabilities for our application. While the entire solution may not be serverless, our backend API is serverless.
Example 3: Jamstack + serverless
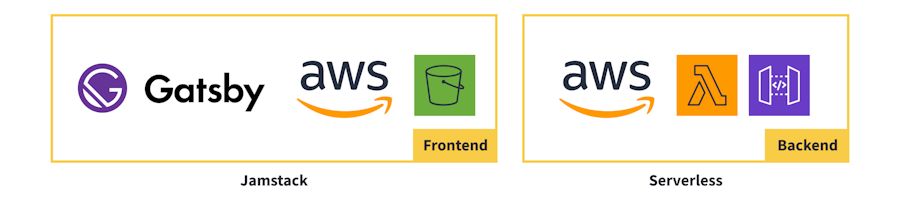
Frontend: Static Gatsby app served from AWS S3
Backend: serverless functions from AWS Lambda and API Gateway
Similar to example 1, we're taking advantage of serving the frontend of our application statically, avoiding any server rendering upfront on the first HTML request, already making it Jamstack friendly.
In addition, we're using an API that relies on serverless functions, making part of this solution serverless as well!
Bringing together Jamstack and serverless
As I alluded to before, the frontend of Jamstack apps can technically be considered serverless. In examples 1 and 3, we're not managing a server, which makes static storage a serverless solution!

Meaning the frontend of Example 1 is serverless, and the entire solution for Example 3 is serverless but also Jamstack friendly.
While they're not necessarily the same thing, there's a ton of overlap, and when combined are a powerful solution!
What's the future of Jamstack and serverless?
Both architectures provide enough benefits that make them compelling to use each on their own. Whether you're looking to offer blazing fast UIs with the Jamstack or infinitely scalable backends with serverless functions, either way, you're in good hands.
But as each technology grows and matures, we start to see more and more overlap between the two.
Jamstack itself could be considered serverless when talking about the frontend. That goes for the traditional static storage or more experimental approaches that use serverless functions to render that document dynamically.
And serverless doesn't necessarily mean Jamstack, but it fits right in and provides similar benefits to a Jamstack frontend.
While we probably won't see the two become one, we'll likely see more significant adoption of the overlap, making Jamstack and serverless a powerful combination for building modern applications for the web.




